

Many marketers, business owners, and even SEO professionals underestimate the importance of technical SEO. For marketers and business owners, it’s pretty understandable. They’re not as well-versed in SEO.
However, even SEO professionals overlook the technical aspect of search engine optimisation. Personally, I believe that technical SEO plays a critical part of any SEO campaign.
What is Technical SEO?
Technical SEO is the process of optimising the technical aspects of your website to assist search engines’ bots in crawling and indexing your website.
It involves implementing specific structures and usability to your site to optimise it for search engine crawlers.
Why is Technical SEO Important?
Think of it this way; technical SEO is the foundation of your website. It forms the basis to anything and everything SEO. If you don’t focus on optimising the technical aspects of your website, you’ll end up spending more resources on on-page and off-page SEO.
Let me provide you with an analogy. Think of technical SEO as the foundation of any building. You definitely can build a building on top of an unstable foundation, but it’ll cost you more in terms of other materials just to make sure the building is structurally sound.
Even with this, well, you don’t remove the risk of the building collapsing. Same goes with SEO; if your technical is not right, anything can happen that will destroy your SEO efforts.
What goes into technical SEO?
Here are the factors that are covered in technical SEO:
- Crawling
- Indexing
- Site architecture
- URL structure
- Broken links
- Redirects
- Website speed
- Mobile responsiveness
- Thin content
- Duplicate content
- Canonical tags
- Structured data
- Hreflangs
- Robots.txt
- Sitemaps
- Website security
- URL Protocol
It may sound confusing, but I’m gonna be honest with you. It is. However, I’ll do my best to explain these in the simplest way as possible.
But before I begin breaking down technical SEO, it is essential to understand how search engines work. Search engines send out crawlers/spiders/bots to the internet. These spiders then crawl the internet to look for pages to be added to their library of websites (aka their index).
As to how these spiders find websites, they crawl the links on websites – be it internal or external links. That’s why it’s called the World Wide Web. Every website is connected to each other like a huge giant web. This process is ongoing as they are continually looking to add more pages into their index.
With this, it’ll be easier to understand what goes into optimising for search engines.
Crawling, Indexing, and Site Structure
As you know, search engine bots crawl the internet to look for other websites. Therefore, it’s critical to make sure that they can crawl your website easily and index them.
The first thing you need to do is to ensure that your site structure is built correctly. This means that the structure of your website needs to be logically arranged. A logically arranged website structure allows easy and proper crawling.
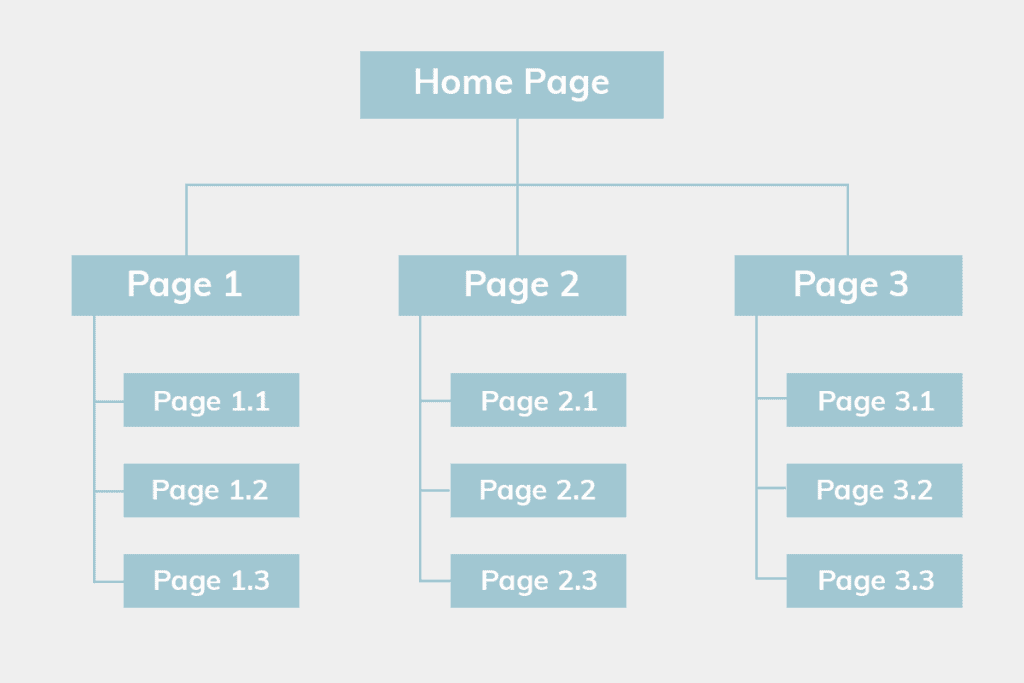
The image above shows a website that has been appropriately structured. With the hierarchical structure above, not only do your visitors know that Page 1.1 belongs to Page 1, but so does the crawlers.
This makes it easy for the crawlers to find all the webpages in your website and allows Google to understand how your website is before deciding to show the most relevant page to searchers.
With a disorganised site architecture, you risk having orphan pages on your website.
Orphan pages are pages on your website that are not in the website architecture. This tends to occur if you don’t follow a flat hierarchy and have missing internal links to said pages. Let me illustrate:
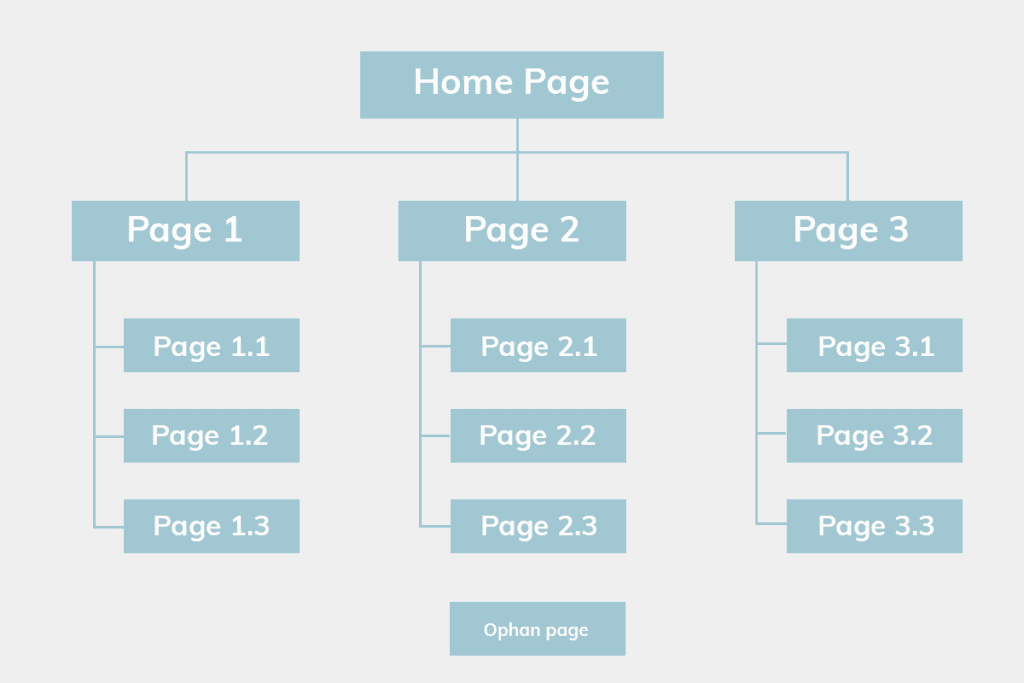
As you can see from the image, there is no way for the crawler to reach that orphan page. If the crawler can’t get that page, search engines can’t index it. This means that the page will never be found on Google at all.
As web crawlers travel through the internet by following links, a good internal linking structure is vital for these bots to find your content. All the webpages in your site should be able to be reached easily to prevent orphan pages.
URL Structure
Another way to improve crawling and indexing is to observe your URL structure. A URL structure is basically how your URL looks. Although this is not entirely necessary for technical SEO, it helps that your URL structure is clean and organised.
With the above illustration, a clean URL structure will look like this:
https://domain.com/page-1/page-1.1/
https://domain.com/page-2/page-2.2/
This is just a good way to structure your URLs, however, if your URLs look like this:
https://domain.com/page-1/
https://domain.com/page-1.1/
it’s fine too. Don’t go changing your URL structures when your website is already established because it’ll cause broken links and unnecessary redirects.
However, what you want to avoid are URL strings that are dynamically generated. For websites that have filtering options (usually e-commerce), your filters might dynamically add URL strings.
These URL strings cause duplicate content that search engines will crawl. This wastes your crawl budget – the resources allocated to your website by search engines.
It’s even worse if they index them. If possible, use a different language such as AJAX so that it won’t add dynamic strings.

Broken Links
Have you ever clicked on a link only to receive a 404 Error: Page not found? Google hates these.
This usually happens when you create an updated post and delete the old one from your website without redirecting the URL to the new one. It also happens when you change URLs without creating redirects.
This is a common mistake that SEOs and web developers make. Always remember to check for broken links in your website and redirect them somewhere that is related.
Redirects
Redirects are basically a way to tell search engine crawlers that the page has moved. There are 3 types of redirects that you need to take note of.
- 301 redirects
- 302 redirects
- 307 redirects
301 redirects tell crawlers that your page has permanently moved from Page A to Page B.
302 redirects tell crawlers that Page A has been temporarily found via Page B.
307 redirects tell crawlers that your page has been temporarily moved from Page A to Page B.
Although they behave the same way by ultimately showing Page B, you will need to take note of which redirect types to use. If you are editing Page A and want to show Page B to users temporarily, then you can use either 302 or 307 redirects.
This does not transfer link equity from Page A to Page B, meaning that by the time you remove the temporary redirect, all the authority still belongs to Page A.
However, a common issue that occurs is that website owners tend to forget to change their 302 and 307 redirects into 301s if they decide that they no longer want to keep Page A. In essence, your link equity will not be passed from Page A to Page B, causing a waste in the link you’ve built.
Some SEOs argue that a 302 and 307 redirect will be regarded as a 301 redirect if it’s been there for a long time. What I recommend is to play it safe and convert them all to 301s.
Redirect Chains
Another common issue webmasters face are redirect chains. A redirect chain, well, is a chain of redirects. Instead of redirecting Page A to Page C, you are redirecting Page A to Page B, which redirects to Page C. Let me illustrate.
You are doing:
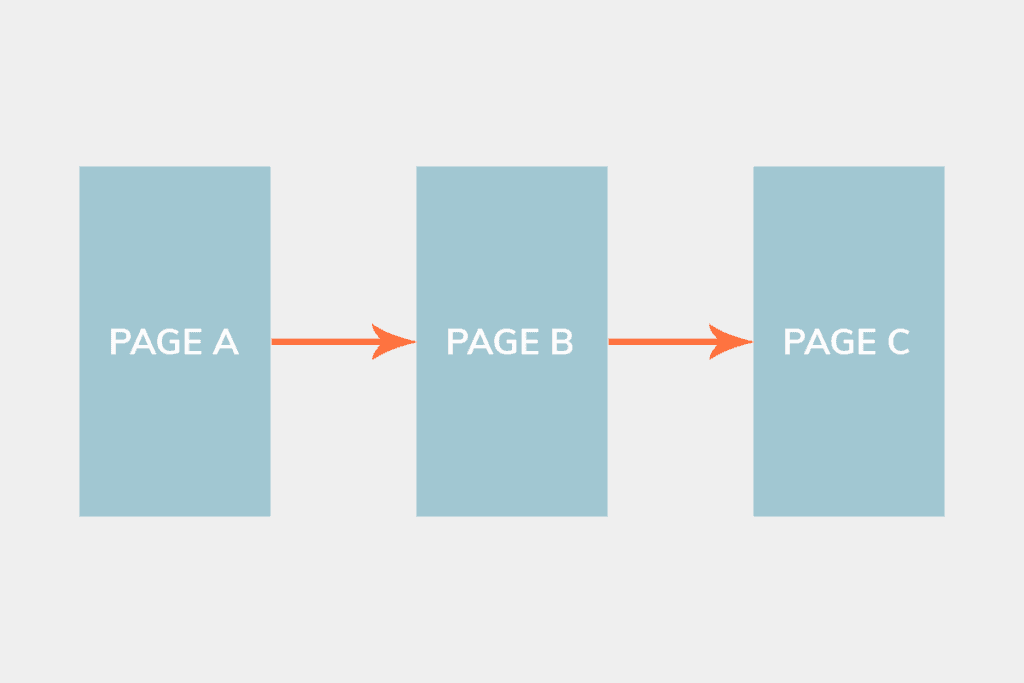
What you should be doing
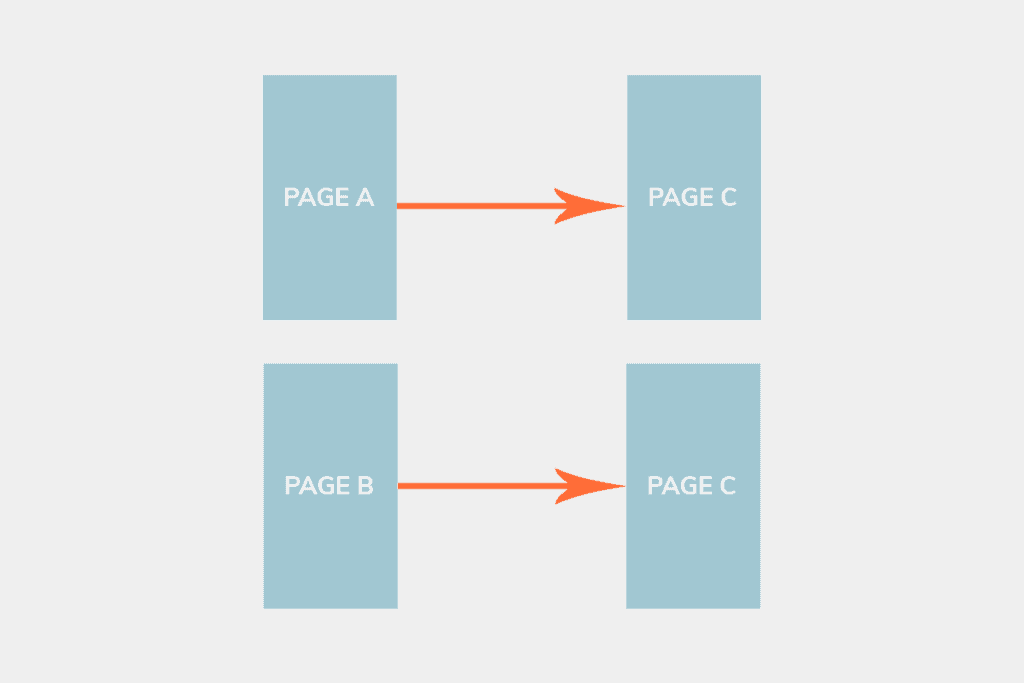
This is a problem in SEO as crawlers will have to crawl 2 different pages (Page A & B) before getting to Page C. Not only are you wasting your crawl budget, you increase the time it takes to load a page.
The longer the time needed to load a page, the higher the chances of your visitors leaving.
The longer the time needed to load a page, the more resources you’re using from search engines.
Therefore, you want to identify and remove redirect chains to conserve your crawl budget and to reduce your loading times.
Website speed
Website speed is one of the most significant ranking factors on Google. The lower your page speed, the higher you’ll rank on Google.
One of the reasons behind this is that Google is prioritising user experience. If someone has to wait 10 seconds to load your page, chances are they’ll leave your website, affecting your rankings negatively!
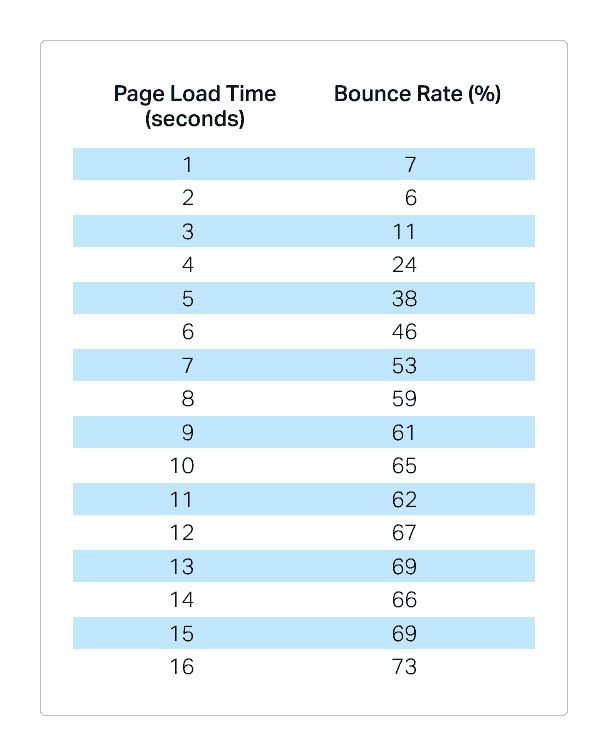
Source: Pingdom
Take a look at the chart above, the longer your page takes to load, the higher the bounce rates! For those who don’t know, bounce rates are
“The percentage of visitors to a particular website who navigate away from the site after viewing only one page.”
Contrary to what many people believe, user-based signals such as bounce rates, clicks, time on page, etc. have indirect effects on SEO. Think about it this way, if someone comes from Google and clicks on your result, only to find out that your website is taking forever to load.
They’ll probably skip and go to another search result. This pogo-sticking effect will cause your rankings to drop. Therefore it is always important to look for ways to reduce your page speeds.
There are many ways to reduce your page speed. For starters, try reducing the number of plugins you’re using. The more plugins you use, the slower your site will be.
Also, you could try caching your website, compress your images, and minify your JavaScript and CSS. I’m not a developer; therefore, I can’t provide you with any further advice on this.
However, if you’re on WordPress, here are some tools that I recommend you use to improve page speeds.

Mobile Responsiveness
Mobile responsiveness plays a massive part in Google’s ranking factor. As the majority of internet users are now on mobile, Google’s shifting its priority to mobile-first. Google also warned that if you’re not prioritising a mobile-friendly website, you’re losing out a quarter of your potential audience.
Make sure that your website is responsive to begin with. If you’re on WordPress, choose a mobile responsive theme in the beginning so that you don’t have much to worry about when designing your website.
If you have a mobile version of your website, try as much as possible to have a responsive version of your website instead. This is because with a mobile version, you’re creating duplicate pages of your website – both the desktop and mobile sites. This uses up additional crawl budget.
If a responsive website is not a choice for now, you could add canonical tags to your mobile version by defining your desktop version as the main version of your website. More on canonical tags later.
Here’s a post that shares some pretty good mobile design tips you can follow.
Thin Content
If your website has any pages with less than 500 words, they are likely considered as thin content. Thin content adds little to no value to your website in the eyes of search engines.
Think of it this way, if there are 20 articles with more than 1,000 words covering the same topic, and yours only has 500 words, which do you think search engines will pick?
The one with more words that answers the search query.
However, not all pages with less than 500 words are considered as thin content. For example, if you can answer the search query with less than 500 words, and all your competitors have similar word counts, it means that Google has determined 500 words is sufficient for the keyword.
Similarly, most “Contact” pages have less than 500 words. Generally, pages like these will do just fine with lesser word count. However, any other pages with low word count should be beefed up.
Here’s what you can do:
- Add more words to make it more than 500. Make sure you’re not adding fluff
- Delete the page (if there’s no value to users) and do a 301 redirect to a related page if you have backlinks to the page
- Delete the page (if there’s no value to users) and use a 410 status code if there are no backlinks to the page
- Add noindex and nofollow meta tags to these pages
- Add canonical tags to these pages

Duplicate Content
Duplicate content are pages on your website that have the exact same information. These pages waste your crawl budget as search engine bots are crawling the same thing over and over again.
Similar to thin content, if crawlers see that you have many of these thin and duplicate content, they’ll regard your website as a low-quality site. They will then restrict their resources in the future and cause you to have your important pages unindexed and un-crawled.
I use siteliner.com to identify duplicate content.
Generally, my rule of thumb is to have below 20% of internal duplicate content within the actual content body itself. This means that sidebars, headers, and footers are generally ignored. Legal notices that are repeated across pages and paginated pages are fine as well.
However, taxonomy pages such as tags, categories, and author pages, and content within the body itself are pages where you should be concerned.
Before you go about making changes to what you see on Siteliner, I’d recommend you add the noindex tags to your taxonomy pages. Once these pages are deindexed, proceed to add a nofollow tag to prevent spiders from crawling them again. You can take an extra step to disallow these pages on your robots.txt file (more on this later too).
Anything else you find on Siteliner will need to be rewritten/rephrased to avoid duplication. Similar to thin content as well, you can follow these steps:
- Rewrite your pages to make each page unique
- Delete the page (if there’s no value to users) and do a 301 redirect to a related page if you have backlinks to the page
- Delete the page (if there’s no value to users) and use a 410 status code if there are no backlinks to the page
- Add noindex and nofollow meta tags to these pages
- Add canonical tags to these pages
Canonical Tags
Say you have various pages with the same content that slightly vary from each other. Instead of rewriting, deleting them, or even adding noindex tags, you could add canonical tags.
What canonical tags do is that they tell search engines that you have very similar pages, but Page A is the main page you want indexed.
For example, if you run an e-commerce store, you might sell the same t-shirt in different sizes and colours. These variations will have the same descriptions with variations in only their features.
Therefore, what you can do is to add the rel=” canonical” tag to the variations by defining the main product you want ranked.
Structured Data
Structured data, more affectionately known as schema markup, are basically codes you add into your pages to help search engines return more informative results. These codes, in its simplest form, tells search engines what your page is exactly about.
For example, an article talking about SEO services in Singapore and a landing page that sells SEO services in Singapore are 2 different things. Sure, it’s generally not recommended to go after the same keyword with 2 different search intents, but let’s try to keep it simple here.
If Google wants to determine which page is the most relevant to the search query, schema markup helps Google with that. Adding the “blogposting” schema to your article and the “services” schema to your landing page makes all the difference.
Well, at least in theory.
Furthermore, schema markup is needed for you to generate rich snippets on the search results. Rich snippets are eye-catching and take up more space in the SERPs. Having rich snippets can improve your CTRs and therefore your SEO as well.
Hreflang Tags
Hreflang tags are tags that tell search engines which language you are using on your website. These tags are mostly applicable if you’re serving international visitors and customers.
That’s because if you have hreflang tags and you have a version of your website in different languages, these tags will show users the language version that they’re searching in.
Robots.txt File
When search engines first visit your website, they see your robots.txt file to identify which pages they should and should not crawl.
And sometimes, webmasters accidentally block search engines from crawling their websites!
By using Google’s robots.txt tester, they will tell you if Google can crawl your website. As previously mentioned, you can use robots.txt to disallow pages you don’t want Google to crawl. This saves your crawl budget and allows Google to prioritise more important pages on your site.
Since the robots.txt file is the first page that search engines visit, you should also include your XML sitemap in it so that your sitemap is the second page that’s visited.
Sitemaps
Sitemaps come in 2 forms – XML and HTML sitemaps.
The most essential type of sitemap you need for SEO is an XML sitemap. This is because it defines the pages that you want Google to crawl and index, and you can submit it to Google Search Console.
Think of it this way, XML sitemaps are like a directory of pages you want Google to index. You tell Googlebots to crawl and index them through this file.
HTML sitemaps, on the other hand, are just regular webpages you see on websites. They act as a directory for both bots and actual users. HTML sitemaps are great to reduce your click depth (the number of clicks it takes to reach a specific page) as it ideally should be below 3 clicks.
Furthermore, HTML sitemaps provide a second layer of crawling just in case you miss out any pages in your XML sitemap! Remember orphan pages? *wink*

Website Security
A growing concern nowadays has to do with the security of your website. To know if your website is secure, check your URL now. If it begins with HTTP instead of HTTPS, chances are it’s not secured.
Having an SSL certificate installed on your website increases user trust and is one of the easiest things to do to improve on your technical SEO.
Google has mentioned that an SSL certificate will play a large part in SEO as they do not want to serve their users with websites that are prone to data interception.
Furthermore, Google Chrome now lets users know when a site is unsecured and provides a warning sign to them before visiting. This deters clicks into your website and reduces your website visitors significantly.
Getting your website secured can be done quickly by investing a small sum yearly for a basic SSL certificate to be installed to your website. Contact your hosting provider to assist you with it.
Alternatively, some hosting providers provide free SSL certification and automatically installs it for you on your website. Just make sure that you are force redirecting it to the HTTPS version.
URL Protocol
Another common yet detrimental technical SEO mistake I always encounter. If your website does not have a standardised URL protocol (or preferred URL), you’re adding more duplicate pages that search engine spiders will crawl.
To the average human:
http://domain.com
https://domain.com
https://www.domain.com
https://www.domain.com/
http://www.domain.com/
https://domain.com/
are all the same page. However, to search engines, these are all different pages. And these pages are serving the same content. This means that duplicate content is crawled 6 times for EACH page.
What you will need to do is to decide on which version you want your preferred URL to be.
Obviously, you’ll want to have the HTTPS version, but you will need to decide if you wish your website to have the non-WWW or the WWW version.
You’ll also need to decide if you want the trailing slash (/) at the back of your URL.
After deciding on the preferred version, you will need to force 301 redirect all the other versions via your server-side configurations.
Therefore, if you’ve decided on the HTTPS, non-WWW, and trailing slash version, all of the above URLs should redirect to https://domain.com/. This conserves your crawl budget and consolidates all link equity into one version.
Do regular technical SEO audits
For you to find the abovementioned issues, you’ll need to do a technical SEO audit. If you’re actively posting new content on your site, I’d recommend doing it every quarter just to be sure everything’s in check. Otherwise, doing it once every 6 months is sufficient as well.
To do this, grab my free technical SEO audit template where you can identify opportunities to boost your SEO efforts. You can then use the recommendations I provide above for specific areas that you have troubles with.
Conclusion
The foundation of most SEO campaigns is to have a website built properly on a technical level. Unfortunately, most developers don’t build websites with SEO in mind.
They build it based on design and whether you’re happy with it. I mean, you can’t blame them, they’re not SEOs after all.
Therefore, if you didn’t get your website built by an SEO, you should be worried. Technical SEO may be time-consuming to execute, and it’s definitely pretty complicated if you don’t have the technical know-how.
If you’re on WordPress, thankfully these opportunities can be easily rectified through various plugins.
However, you’ll still need to look into it at least once every 6 months just to make sure that everything’s fine. Remember, without a technically sound website, you’ll only be spending more time and money to achieve the same results.
I hope that this article helped break down the different aspects of technical SEO. If you like my content, do join my Telegram SEO channel where I talk about the latest news on SEO and provide my objective perspective to it!



